-17.png)

RP2K: A Large-Scale Retail Product Dataset for Fine-Grained Image Classification
Jingtian Peng ¹ Chang Xiao ² Yifan Li ¹
¹ Pinlan Data Technology Co,. Ltd.
² Columbia University
1. Abstract
We introduce RP2K, a new large-scale retail product dataset for fine-grained image classification. Unlike previous datasets focusing on relatively few products, we collect more than 500,000 images of retail products on shelves belonging to 2000 different products. Our dataset aims to advance the research in retail object recognition, which has massive applications such as automatic shelf auditing and image-based product information retrieval.
Our dataset enjoys following properties:
(1) It is by far the largest scale dataset in terms of product categories.
(2) All images are captured manually in physical retail stores with natural lightings, matching the scenario of real applications.
(3) We provide rich annotations to each object, including the sizes, shapes and flavors/scents. We believe our dataset could benefit both computer vision research and retail industry.
2. Paper

3. Our RP2K dataset

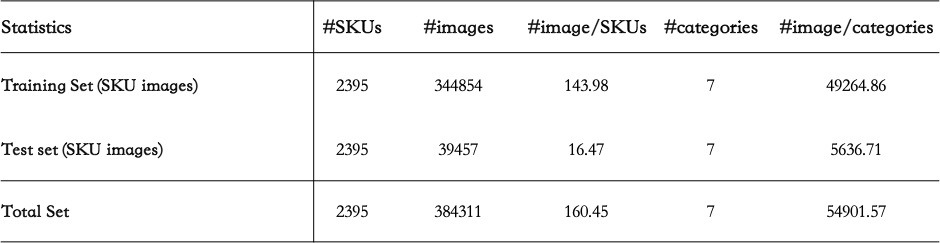
3.1 Overview information of the RP2K dataset
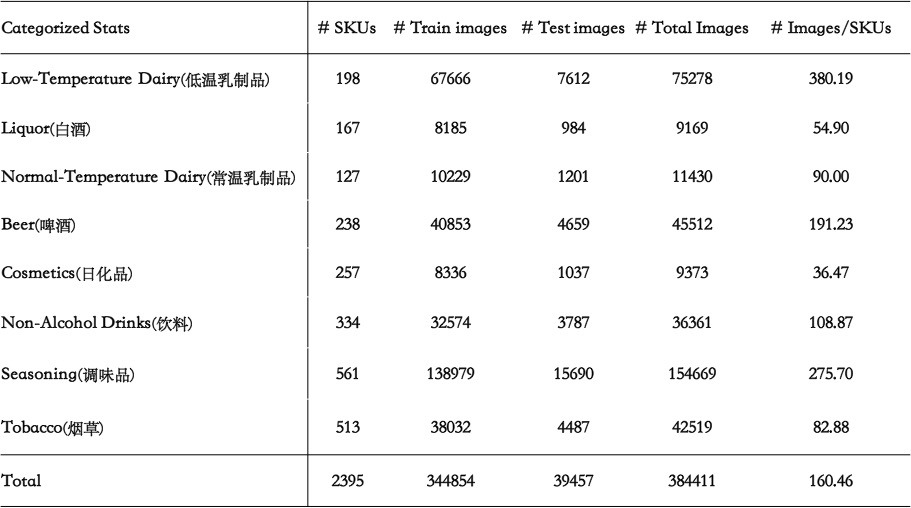
3.2 Categorized information of the RP2K dataset
4. Sample Images
Sample images from our dataset. Precise retail product recognition on shelves is considered highly challenging because (a) Products from the same line may have different sizes, and they usually have similar appearances but different prices. The image size could not reflect the real size of the products.(b) The manufacturer usually make multiple flavors for one product line, but their appearance only have subtle differences on the labels.(c) Product images may be captured at different camera angles according to its placement location on shelves. The image can also be stretched due to camera distortion.

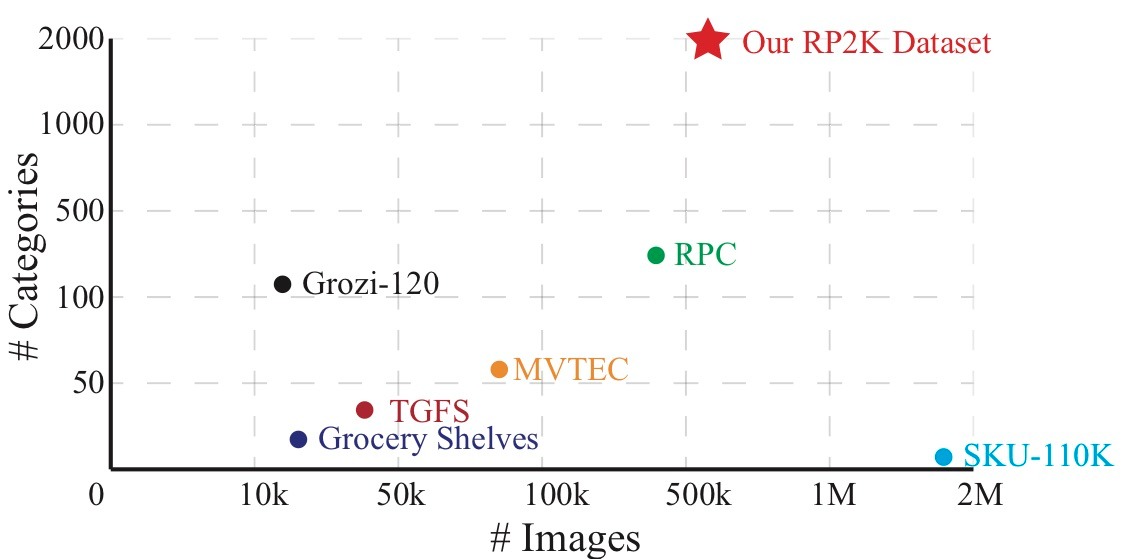
5. Peer Comparison
Comparing to other datasets, our dataset shows considerably larger number of categories, while maintaining a decent amount of images.
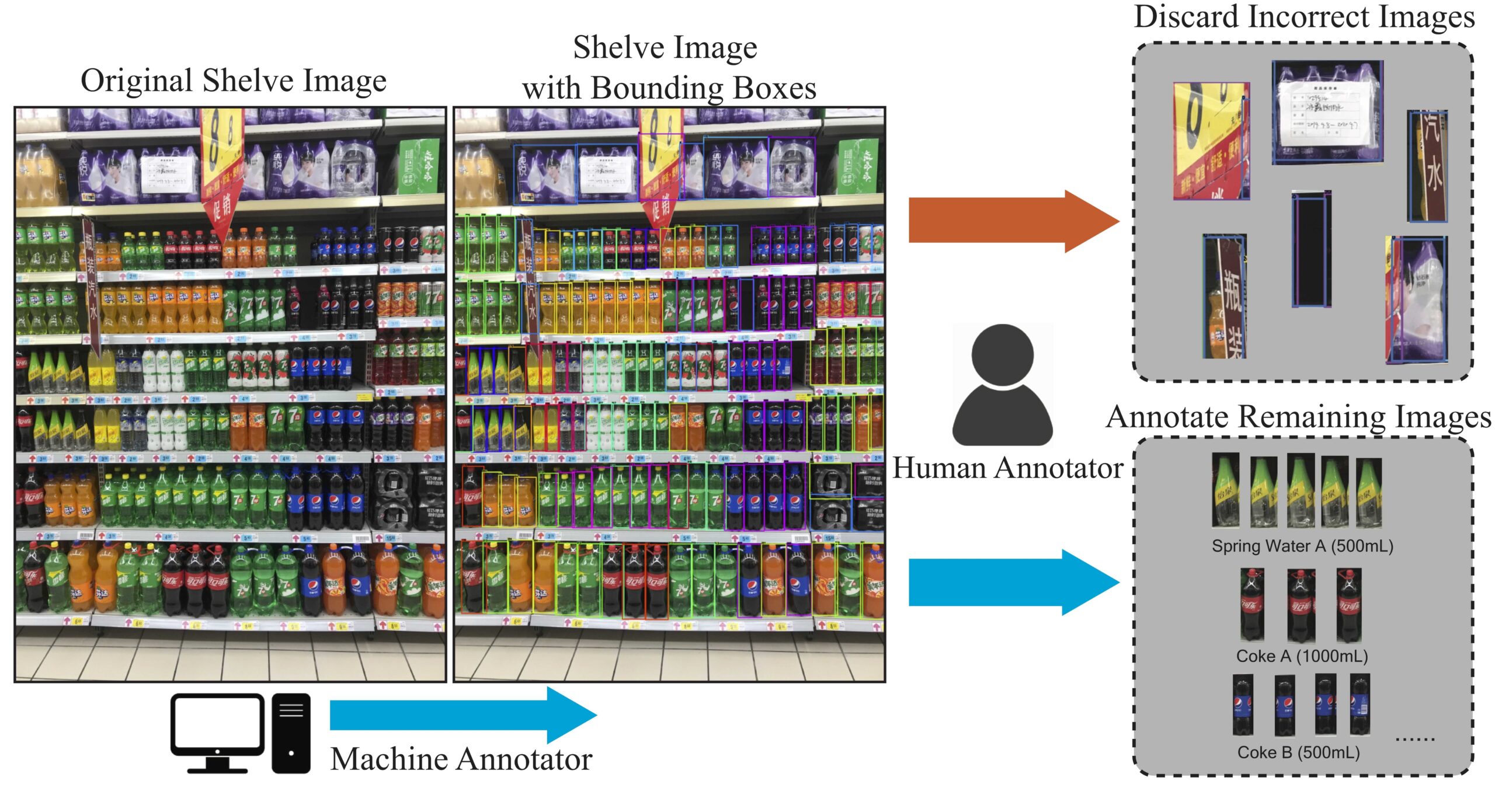
6. Data Collection Pipeline
Pipeline of our data collection process. Our photo collectors were first distributed in over 500 different retail stores and collected over 10k high-resolution shelf images. Then we use a pre-trained detection model to extract the bounding boxes of potential objects of interests. After that, our human annotators discard the incorrect bounding boxes, including heavily occluded images and images that is not a valid retail product. The remaining images are annotated by the annotators.
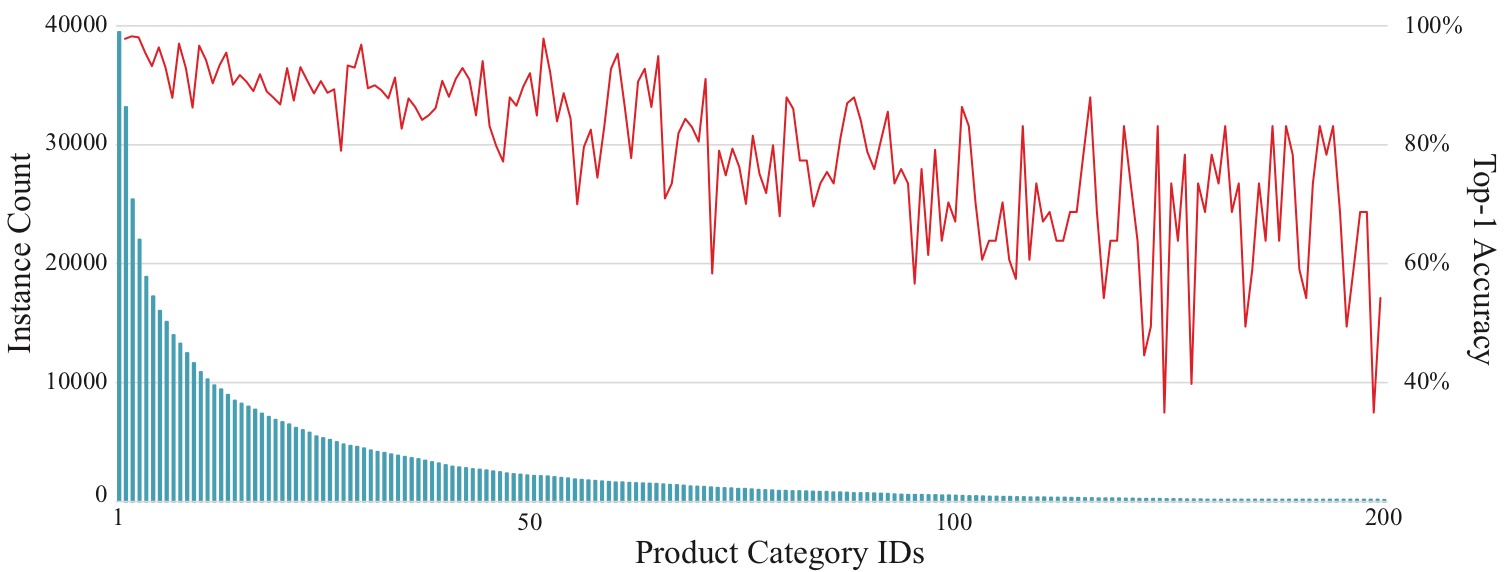
7. Long Tail Problem in Fine-grained Recognition
Long tail problem in fine-grained recognition. With the decreased number of available images, the recognition accuracy is tend to decrease.
8. ATTENTION
This dataset and code packages are free for academic usage. You can run them at your own risk. For other purposes, please contact the corresponding author Jingtian Peng (pjt@pinlandata.com)
@article{peng2020rp2k,
title={RP2K: A Large-Scale Retail Product Dataset forFine-Grained Image Classification},
author={Peng, Jingtian and Xiao, Chang and Li, Yifan},
journal={arXiv preprint arXiv:2006.12634},
year={2020}
}
